Search Engine Optimization (SEO) is a vast field, and for website owners or digital marketers, content creation and optimization can feel like a never-ending task. Fortunately, tools like SEO Content Machine simplify the process by enabling users to scrape, refine, and reuse existing content. This technique can save time while helping you boost your Google rankings.
In this comprehensive guide, we’ll break down the process of using SEO Content Machine for effective content scraping, explain the difference between static and dynamic scrapers, and provide actionable tips to optimize the scraped content ethically.
Introduction to Content Scraping
Content scraping is the process of extracting specific information from web pages and reusing it for SEO purposes, whether for blogs, private blog networks (PBNs), or other web properties. While the practice can be controversial, it is perfectly legal and ethical if done responsibly - such as scraping your own content or repurposing public domain material.
Chris Palmer's video covers the intricacies of leveraging SEO Content Machine, a powerful software, for scraping and reusing content. In this article, we’ll break the process into digestible steps and highlight valuable tips to maximize efficiency and avoid common pitfalls.
What Is SEO Content Machine?
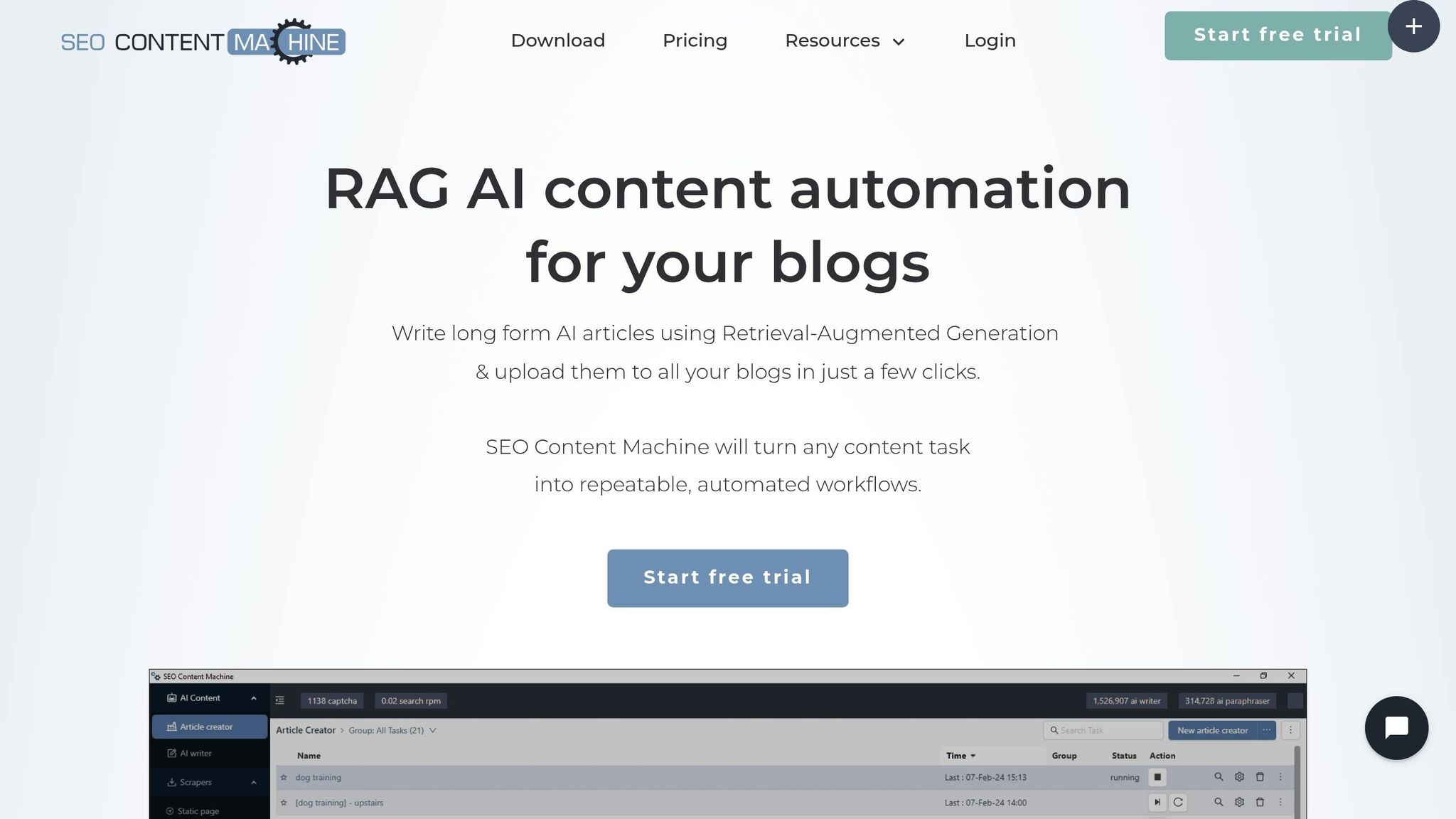
SEO Content Machine is a Windows-based tool designed to automate content generation. Among its many features, it includes two types of web scrapers:
- Static Scraper: Ideal for websites with standardized structures using basic HTML tags like
<H1>or<P>. This works best for most sites. - Dynamic Scraper: A more advanced scraper used for websites with complex coding, dynamic elements, or nested content structures. It uses jQuery selectors to target specific elements.
Both scrapers allow users to extract content (like titles, headings, and body text) and refine it for reuse.
Setting Up a Cloud Instance for WordPress
Before diving into scraping, it’s essential to set up your infrastructure for hosting content. If you’re working with WordPress, you can leverage Google Cloud to create a robust and affordable hosting environment. Here's a simplified outline of the setup process:
- Enable APIs on Google Cloud: Turn on the necessary APIs like Cloud DNS and Load Balancer.
- Choose the Right Cloud Instance:
- Consider cost and resource needs (e.g., memory, virtual cores).
- Look for cheaper instances like E2 or N1 zones.
- Deploy WordPress: Install WordPress and configure PHP MyAdmin for database management.
- Reserve a Static IP: Set up an external static IP address to ensure consistent site accessibility.
- Configure Cloud DNS: Create DNS records (A records, name servers) to connect your domain to your server.
- Add a Load Balancer: Ensure security with SSL certificates and enhance speed through load balancing.
How to Use Static Scrapers in SEO Content Machine
The static scraper is the simpler of the two options, designed to extract content from websites with traditional HTML structures. Here’s a step-by-step guide:
1. Setting Up the Scraper
- Open SEO Content Machine and select the "Static Page Scraper" option.
- Enter the URLs of the web pages you want to scrape (e.g., your website or public content sources).
2. Define the Tags to Scrape
- Specify which tags or elements to scrape, such as:
- Titles (
<title>) - Headings (
<H1>,<H2>,<H3>) - Paragraphs (
<P>)
- Titles (
3. Customize Settings
- Remove unwanted tags (e.g., advertisements or competitor links).
- Set a minimum word count to ignore short or irrelevant articles.
- Translate or spin the text if needed.
4. Save and Run
- Name your scraper task and specify where to save the output files.
- Click "Run" to start scraping.
Common Issues and Solutions
- If the scraper pulls too much irrelevant content, adjust your tag selection.
- If a page has unique or non-standard tags, consult a jQuery selector reference to refine your configuration.
How to Use Dynamic Scrapers for Complex Websites
The dynamic scraper is designed for websites with advanced coding or JavaScript frameworks. While it requires more effort, it’s highly effective for retrieving specific elements.
1. Prepare the Dynamic Scraper
- Select "Dynamic Page Scraper" in SEO Content Machine.
- Enter the target URL and open the page within the tool.
2. Use jQuery Selectors
- Highlight elements on the page you want to scrape (e.g., headings, images, or text blocks).
- Ensure that selected items are marked green in the interface.
- Green indicates a successful dynamic selection.
- Yellow or red suggests overlapping or unrecognized elements.
3. Add Elements to Scraper
- Organize selected elements into a logical structure for output (e.g., heading first, followed by text).
- Save your configuration.
4. Run and Review
- Execute the scraper and review the output file.
- Troubleshoot issues by refining your selectors or testing smaller sections of the page.
Pro Tip: Avoid Over-Scraping
Dynamic scraping can be resource-intensive and may trigger security measures on certain websites. Mitigate risks by using residential rotating proxies like Storm Proxies.
Ethical Considerations for Content Scraping
While content scraping is a powerful tool, it comes with ethical and legal responsibilities. Follow these guidelines to ensure responsible use:
- Scrape Your Own Content: Use the tool to back up or repurpose your own content.
- Respect Copyright Laws: Avoid scraping copyrighted material unless you have permission.
- Cite Your Sources: If reusing public information, credit the original author.
- Don’t Overload Servers: Use proxies to avoid overloading a target website’s server.
Key Takeaways
- Understand Scraping Types: Use static scrapers for standard websites and dynamic scrapers for complex ones.
- Leverage SEO Content Machine: This tool simplifies the process of scraping, formatting, and reusing content.
- Set Up Robust Hosting: Google Cloud provides affordable and secure hosting for WordPress.
- Master Selectors: Learn basic jQuery selectors to refine your scraping process.
- Use Proxies: Protect your IP and avoid rate limiting with rotating residential proxies.
- Stay Ethical: Always respect copyright and legal boundaries when scraping content.
Conclusion
Scraping and reusing content can be a game-changer for SEO, saving time and effort while boosting organic visibility. With tools like SEO Content Machine, even complex tasks like dynamic scraping become manageable. However, success depends on understanding the nuances of scraping, configuring tools effectively, and adhering to ethical practices.
By following the steps outlined in this guide, you can confidently scrape and repurpose content to strengthen your SEO strategy while staying on the right side of the law.
Source: "Google AI Ranking: GEO SEO Without AI SEO Tools in 2025" - Chris Palmer SEO, YouTube, Sep 17, 2025 - https://www.youtube.com/watch?v=KIsA9sQz5Io
Use: Embedded for reference. Brief quotes used for commentary/review.