Robots.txt is a file that provides instructions to web crawlers on which pages of your website they can access. It's part of the Robots Exclusion Protocol and helps optimize crawling, indexing, and search visibility.
Related video from YouTube
Key Benefits of Robots.txt
- Controls which areas web crawlers can access
- Optimizes your crawl budget and server resources
- Guides search engines to focus on important content
- Prevents indexing of private or duplicate content
Creating a Robots.txt File
- Create a plain text file named "robots.txt"
- Specify which web crawlers the rules apply to (e.g.,
User-agent: *for all,User-agent: Googlebotfor Google) - Add
AllowandDisallowdirectives for directories or pages - Include your sitemap location with the
Sitemap:directive - Save and upload the file to your website's root directory
Best Practices
- Keep it simple - only include necessary directives
- Test and validate your rules regularly
- Avoid blocking important content or resources
- Review and update as your website changes
- Use version control to track modifications
By following best practices and maintaining your robots.txt file, you can optimize your website's crawlability, indexing, and search visibility.
How Robots.txt Works
Defining Robots.txt
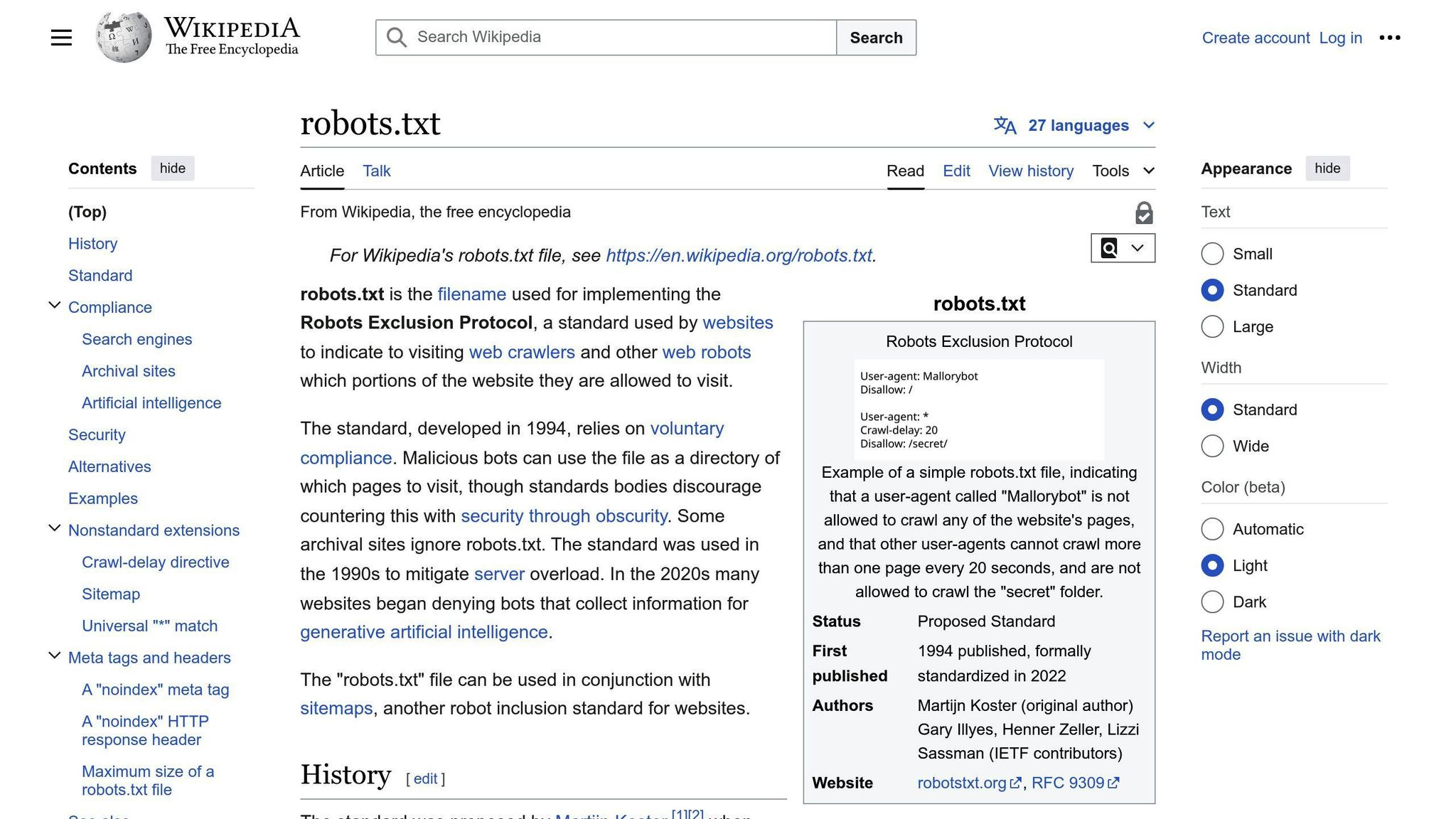
A robots.txt file is a simple text file that tells web crawlers how to crawl and index pages on a website. It's part of the Robots Exclusion Protocol (REP), a set of rules that govern how web robots interact with websites.
The primary purpose of a robots.txt file is to communicate which areas of a website should be accessible to web crawlers and which should be off-limits.
Robots.txt Structure
A robots.txt file consists of two main components: user-agent directives and path directives.
User-Agent Directives
These directives specify which web crawler(s) the instructions apply to.
| User-Agent Directive | Description |
|---|---|
User-agent: * |
Applies to all web crawlers |
User-agent: Googlebot |
Applies to Google's web crawler |
Path Directives
These directives indicate which URLs or directories should be allowed or disallowed for crawling.
| Path Directive | Description |
|---|---|
Disallow: /private/ |
Blocks access to the "/private/" directory |
Allow: /public/ |
Allows access to the "/public/" directory |
Other directives like Sitemap and Crawl-delay can also be included to specify the location of the website's sitemap and control the crawl rate, respectively.
Robots.txt and SEO
A well-configured robots.txt file plays a crucial role in optimizing a website's crawl budget and improving its overall SEO performance.
By directing web crawlers to the most important pages and preventing them from wasting resources on irrelevant or duplicate content, a properly structured robots.txt file can:
- Enhance crawling efficiency
- Improve indexing accuracy
- Boost search visibility for valuable content
However, it's important to note that robots.txt is not a foolproof method for preventing content from being indexed. Search engines may still index pages that are linked from other websites, even if they are disallowed in the robots.txt file. For complete content exclusion, additional methods like password protection or the "noindex" meta tag should be employed.
sbb-itb-b8bc310
Creating a Robots.txt File
Steps to Make a Robots.txt File
To create a robots.txt file, follow these simple steps:
1. Create a plain text file: Open a text editor like Notepad (Windows) or TextEdit (Mac) and create a new file. Name it "robots.txt" and save it with the ".txt" extension.
2. Specify user-agents: Define which web crawlers the rules apply to:
User-agent: * # Rules for all crawlers
User-agent: Googlebot # Specific rules for Google
3. Add allow/disallow directives: List the directories or pages you want to allow or block access to:
User-agent: *
Disallow: /private/ # Block access to /private/ folder
Allow: /public/ # Allow access to /public/ folder
User-agent: Googlebot
Disallow: /thank-you/ # Block Googlebot from specific pages
4. Include sitemap location (optional): Provide the URL of your website's XML sitemap to help search engines discover content:
Sitemap: https://www.example.com/sitemap.xml
5. Save and upload to root directory: Save the file and upload it to your website's root directory (e.g., www.example.com/robots.txt).
Testing Your Robots.txt File
To ensure your robots.txt file is working correctly, follow these steps:
1. Check for errors: Use Google's Robots.txt Tester to validate your robots.txt file and identify any syntax issues.
2. Test crawler access: Visit your website with a private/incognito browser window and check if restricted pages are accessible or blocked as intended.
3. Monitor crawl stats: Review your website's crawl stats in Google Search Console to ensure search engines are following the directives correctly.
4. Regularly review: Periodically check your robots.txt file, especially after making website changes, to ensure it remains up-to-date and accurate.
Common Mistakes and Best Practices
Mistakes to Avoid:
| Mistake | Description |
|---|---|
| Blocking important resources | Blocking CSS, JavaScript, or image files can affect website functionality |
| Disallowing the entire website | Using Disallow: / can prevent search engines from crawling your website |
| Using absolute paths | Using absolute paths instead of relative paths can lead to errors |
| Forgetting to list specific user-agents | Failing to specify user-agents like Googlebot can lead to incorrect crawling |
Best Practices:
| Best Practice | Description |
|---|---|
| Use wildcards carefully | Avoid overblocking by using wildcards carefully |
| Test changes thoroughly | Test changes before implementing them |
| Keep the file simple | Allow access by default and only disallow specific pages or directories |
Leverage the Sitemap directive |
Use the Sitemap directive to help search engines discover content |
| Review robots.txt regularly | Regularly review your robots.txt file to ensure it remains up-to-date and accurate |
Advanced Robots.txt Usage
Using Wildcards and Patterns
Robots.txt files support the use of wildcards and pattern matching to specify URL paths more flexibly. The asterisk * is a wildcard that matches any sequence of characters. For example:
| Pattern | Description |
|---|---|
Disallow: /private/* |
Blocks all URLs starting with /private/ |
Disallow: /*.php |
Blocks all URLs ending with .php |
Disallow: /*?* |
Blocks all URLs with a query string |
Combining wildcards enables powerful pattern matching for directories, file types, and URL structures.
Sitemap and Crawl-Delay Directives
The Sitemap directive specifies the location of your website's XML sitemap, helping search engines discover your content:
Sitemap: https://example.com/sitemap.xml
The Crawl-delay directive instructs crawlers to wait a specified number of seconds between requests:
Crawl-delay: 10 # Wait 10 seconds between requests
This can help manage server load, but be cautious as excessive delays may limit how quickly your site is crawled and indexed.
Case-Sensitive Paths and User-Agent Rules
Paths specified in Allow and Disallow directives are case-sensitive. For example, Disallow: /FOLDER/ does not block /folder/. To account for this, you may need to specify both cases.
You can also create user-agent specific rules by grouping directives under a User-agent line:
User-agent: Googlebot
Disallow: /private/
User-agent: *
Disallow: /admin/
This allows you to control access for different crawlers, such as blocking the /private/ directory for Googlebot while disallowing the /admin/ path for all other user agents.
Robots.txt and Website Performance
Robots.txt plays a vital role in optimizing website performance by controlling how search engine crawlers access and index your content. Proper configuration can significantly impact your search rankings and user experience.
Controlling Crawler Traffic
By specifying which pages to crawl and which to ignore, robots.txt enables you to direct crawlers to your most valuable content. This optimizes your crawl budget, ensuring that high-priority pages are indexed first and less important areas are deprioritized.
Securing Sensitive Content
Robots.txt allows you to prevent crawlers from accessing sensitive information, such as private user data or confidential business details. However, it's essential to note that robots.txt is not a security mechanism and should be used in conjunction with other measures.
Pros and Cons of Robots.txt
| Pros | Cons |
|---|---|
| Controls crawler access to your site | Not legally binding; malicious bots may ignore it |
| Optimizes crawl budget for better indexing | Misconfiguration can block important pages |
| Prevents indexing of non-public areas | Disallowed pages may still be indexed via external links |
| Guides crawlers to focus on important content | Limited control over specific crawler behavior |
| Reduces server load from unnecessary crawling | Requires ongoing maintenance and updates |
While robots.txt offers significant benefits for SEO and performance, it's essential to weigh its limitations and potential risks. Careful implementation and regular maintenance are key to maximizing its advantages while mitigating potential issues.
Robots.txt Best Practices
Crafting an effective robots.txt file is crucial for optimizing your website's crawlability and search engine visibility. Here are some key best practices to follow:
Do's and Don'ts for Robots.txt
Do:
- Keep it Simple: Start with a basic robots.txt file and only add complexity as needed.
- Use Wildcards Carefully: Wildcards like
*can be powerful but should be used judiciously to avoid blocking important content. - Test and Validate: Use tools like Google's Robots.txt Tester to ensure your directives are working as intended before deploying.
- Link to Your Sitemap: Include a
Sitemap:directive pointing to your XML sitemap to help search engines discover your content. - Document Changes: Maintain a changelog or comments within the file to track modifications and their reasons.
Don't:
- Block Important Content: Avoid disallowing critical pages, resources, or entire directories unless absolutely necessary.
- Forget Case Sensitivity: URLs are case-sensitive, so ensure your directives match the exact casing.
- Use Trailing Slashes Incorrectly: Be mindful of trailing slashes in your directives, as they can affect how URLs are interpreted.
- Rely Solely on Robots.txt: While useful, robots.txt should be combined with other SEO techniques and not treated as a silver bullet.
- Neglect Updates: Regularly review and update your robots.txt file to reflect changes in your website's structure and content.
Maintaining Your Robots.txt File
Your robots.txt file is not a set-it-and-forget-it asset. As your website evolves, you'll need to maintain and update your robots.txt file accordingly:
| Task | Description |
|---|---|
| Monitor Changes | Keep track of new content, restructuring, or additions that may require updates to your robots.txt rules. |
| Review Regularly | Set a recurring schedule (e.g., quarterly) to review your robots.txt file and ensure it aligns with your current SEO goals and website structure. |
| Stay Updated | Keep an eye on search engine updates and best practices related to robots.txt files, as recommendations may change over time. |
| Use Version Control | Implement version control for your robots.txt file to track changes, revert if needed, and collaborate with your team effectively. |
| Leverage Tools | Utilize monitoring tools and crawl reports from search engines to identify potential issues or areas for optimization in your robots.txt file. |
By following these best practices and maintaining your robots.txt file, you can ensure that search engines can effectively crawl and index your website, leading to better visibility and user experience.
Conclusion: Using Robots.txt for SEO
A well-crafted robots.txt file is crucial for optimizing your website's crawlability and search engine visibility. By providing clear instructions to web crawlers, you can control which pages are indexed, manage your crawl budget, and prevent duplicate content issues.
Key Takeaways
To leverage robots.txt for SEO success, follow these best practices:
- Keep your robots.txt file simple and organized.
- Test and validate your directives regularly.
- Link to your XML sitemap to help search engines discover your content efficiently.
- Avoid blocking important pages or resources unless necessary.
- Maintain and update your robots.txt file as your website evolves.
Why Robots.txt Matters
A well-optimized robots.txt file can:
- Improve search engine rankings
- Enhance the overall user experience
- Help search engines understand your website's structure and content
Remember, a well-optimized robots.txt file requires regular maintenance and adaptation to changes in your website's structure and content. Stay vigilant, test frequently, and leverage the power of robots.txt to its fullest potential for SEO success.
FAQs
What does robots.txt tell you?
Robots.txt is a file that tells web crawlers which URLs they can or cannot access on your website. It helps prevent your site from being overloaded with too many requests. However, robots.txt is not a way to prevent web pages from being indexed by Google. To keep a page out of Google's index, use the noindex meta tag or password-protect the page.
Is robots.txt good for SEO?
Yes, robots.txt is important for SEO. It helps search engines crawl your website efficiently by guiding them to the most important pages and content. A well-optimized robots.txt file can improve your site's crawlability, indexing, and ultimately, search engine rankings.
What is the overall best practice with a robots.txt file?
Here are some best practices for optimizing your robots.txt file:
| Best Practice | Description |
|---|---|
| Keep it simple | Only include necessary directives for your site. |
| Be specific | Use precise URL patterns and avoid broad rules. |
| Monitor and update | Regularly review and update your robots.txt as your site changes. |
| Link to your sitemap | Include a directive pointing to your XML sitemap for better crawling. |
| Test and validate | Use tools like Google's Robots.txt Tester to ensure your directives work as intended. |
| Avoid noindex directives | Use the noindex meta tag instead of robots.txt to prevent indexing. |
| Prevent UTF-8 BOM | Ensure your robots.txt file does not include the UTF-8 Byte Order Mark (BOM), which can cause parsing issues. |
By following these best practices, you can optimize your robots.txt file for better SEO performance and search engine visibility.